

文章最後修改於 2026-01-16
nofollow 是什麼?SEOer 常忽略的連結管理祕技,錯過恐失排名優勢!
nofollow 是一種 HTML 標籤屬性,寫法是 rel=”nofollow”。
nofollow 主要用在連結上,目的是告訴搜尋引擎「別追蹤這個連結,也不要傳遞網站的影響力(權重)」。
這種用法主要是為了對付垃圾連結。
早期很多人會在留言區或論壇到處貼自己的網站連結,想藉此提升排名,但這些連結往往和張貼頁面無關,甚至是內容南轅北轍的廣告連結。
搜尋引擎需要方法來搞懂哪些連結應該被信任推廣,哪些不應該影響排名。
於是,Nofollow 就誕生了!透過設定 nofollow,這些惡意連結就不會影響搜尋排名,網站排名也不會因此被牽連。
簡單說,nofollow 就是一種表態,傳達出「這個連結的內容我不擔保,也不推薦」的態度。
(一)nofollow 對 SEO 的影響?
除了防止垃圾連結,在網站上設定 nofollow 還有其他用途,尤其是網站管理方面。
- 促使網站管理者建立高品質連結
當自身網站連結到外部網站時,會將部分權重傳遞給這些外部連結的目標頁面。
透過在連結中加入 rel=”nofollow”,我們就可以告訴搜尋引擎不要追蹤該連結,防止將權重傳遞出去、集中自身網站的權重。
除了外部連結,內部頁面也有些頁面不需要獲得額外的權重,例如常見的「隱私政策」或「服務條款」頁面。
SEOer 對這些連結使用 rel=”nofollow”,可以把網站編輯重心重新聚焦回核心「提供使用者正確又優質的內容」,更能遵守搜尋引擎的規範。
- 控制搜尋引擎爬蟲抓取效率
搜尋引擎爬蟲在掃描網站時,會沿著連結一個一個去抓取網頁內容。
如果在一些不重要的連結上使用 Nofollow,比如「登入頁面」或「隱私政策」,爬蟲就不會浪費時間去抓取這些頁面,而是專注在更重要的內容上。
這樣一來,爬蟲資源就能被更有效率地利用,幫助網站更快入速、準確地被索引。
(二)nofollow 對 SEO 的好處?
- 避免與垃圾連結掛勾,提升網站排名
nofollow 可以讓你的網站跟垃圾連結撇清關係,避免因為這些無關連結被拖累排名。
當網站上有一些不重要或不相關的外部連結,就像是廣告、合作夥伴的連結,使用 nofollow 可以告訴搜尋引擎不用分配權重到這些連結上。
如此一來網站的權重就能留給內部的重要頁面或高關聯性的外部連結,讓搜索引擎更專注在你希望推廣的內容上,集中權重。
- 維持網站的可信性
如果你的網站有其他用戶留言內容(像是留言區或論壇),其中可能出現一些無關內容或垃圾連結。
為這些連結加上 nofollow ,搜尋引擎就不會認為你在幫它們背書,這樣可以保護你網站的信任度不被影響。
長期來看,不僅能穩定排名,還能間接提升頁面的排名表現。
- 避免權重外流
網站管理者可以利用 nofollow 精準地控制網站權重的流向。
當自身網站連結到外部網站時,會將部分權重傳遞給這些外部連結的目標頁面。
在連結中加入 rel=”nofollow”,我們就可以告訴搜尋引擎不要追蹤該連結,防止將權重傳遞出去、集中自身網站的權重。
除了外部連結,在內部頁面也可能有某些頁面不需要獲得額外的權重,例如常見的「隱私政策」或「服務條款」頁面。
對這些連結使用 rel=”nofollow”,可以避免權重傳遞到這些頁面,集中更多權重,保留給更重要的頁面,優化 SEO 成效。
換句話說,當我們的網站連結被放在外部高流量的網站上,即使對方在後台設置 nofollow,
雖然不會傳遞權重,但使用者還是能點擊進入,一樣能為網站帶來實際的流量。
增加曝光機會就對提升品牌知名度和影響力有所幫助。
別再亂用 rel=’nofollow’!3 種應用情境一次搞懂!
(一)向外站付費購買的宣傳連結
舉例來說,身為一個零食品牌,想為即將上市的新產品打廣告提升知名度,手法之一會邀請眾多網紅利用其知名度分享新產品,也就是所謂的「業配」廣告。
但這些網紅的部落格平時分享的內容很可能充斥五花八門的議題,其他與我們品牌網站的無關內容會降低關聯性,甚至可能搜尋引擎判定是黑帽 SEO 操作,完全是得不償失的行為。
因此需要請對方使用 nofollow 來讓搜尋引擎明白雙方的網站並不願意建立關聯。
也不是說所有付費連結都需要使用 nofollow 屬性,而是需要以付費連結的網站內容及網站文章的關聯性判斷。
若是付費連結的外部網站很明顯的與自身品牌文章毫無關聯,那麼我們最好就加上 nofollow 以免被搜尋引擎懲處。
(二)新聞媒體網站
這裡討論的媒體網站可以舉例像是《GQ》、《Vogue》等主要以時事、潮流和生活方式之類的媒體網站。
網路媒體網站內文常會需要提及其他網站或品牌、商業資訊,因此會使用 nofollow 表明內文連結只是提供使用者更多資訊參考,並不代表媒體推薦或背書。
這樣可以避免搜尋引擎將權重傳給外部網站,保護雜誌自身的權威性和排名表現。
(三)留言評論區
許多網站會開放使用者對於文章內容留言討論,像 PTT、Dcard 等公開論壇,因為大部分內容都是網友隨意發的。
因為人人都能編輯的特性讓留言區可能成為垃圾連結的溫床,有心人可能利用評論區發佈無關或惡意的連結,試圖提升自己網站的排名。
為了避免自身網站被無關內容降低權重分數,同時表達網站不為其言論背書,因此我們通常會在這類型的網站加上 rel=”nofollow” 維護網站權威。
(四)不願連結的網站
SEOer 都會有的概念是:Google 使用 E-E-A-T(經驗、專業知識、權威性、可信度)來評估網站內容的品質。
如果被引用的網站在這些方面表現不佳,那麼建立連結很可能會拖累自身評分。
我們可能會因為撰寫「負面案例」而需要引用不願連結的網站內容;或是針對外站討論區進行文章回復。
在這些情況下使用 rel=”nofollow” 告訴搜尋引擎「我提到這個網站,但不代表我推薦它」,也不希望傳遞權重給它。
舉個例子,當我們撰寫一篇穿著相關的文章,引用了非專業人士撰寫的部落格,而該部落格內容沒有經過專家審核、或是你無法完全確定其可靠性,這樣的引用就屬於品質不高的網站。
新手小白都能看懂!3步驟正確使用 rel=”nofollow”!
nofollow 在 HTML 語法是 rel=”nofollow”,也就是將 rel=”nofollow” 在原始碼編輯模式中加到任何你想使用 nofollow 的連結網址後就完成了。
- 後台進入 HTML 原始碼編輯模式。
實際操作舉例:
https://adbest.com.tw/ 這段網址
- 找到想設定 nofollow 的連結及錨文字,在語法中加上 rel=”nofollow” 。
一般正常連結語法為:
<a href=”https://adbest.com.tw/″>錨文字</a>
若是想要使用 nofollow 屬性,這時候語法需要修改成:
<a href=”https://adbest.com.tw/” rel=”nofollow”>錨文字</a>
- 確認正常點擊
最後再次進入前台確認編輯無誤,呈現的錨文字連結可以正常點擊就完成設置了。
如此一來我們就可以很簡單的向搜尋引擎說明雙方網站並無關係,不需要分配網站權重。
四如何查看 nofollow 教學?2 種小白都能懂超簡單檢查技巧!
從使用者的角度來看,我們在網頁上是看不出來連結有沒有設定 Nofollow 。所以,接下來教你 2 種方法,幫你快速檢查連結是不是設了 Nofollow。
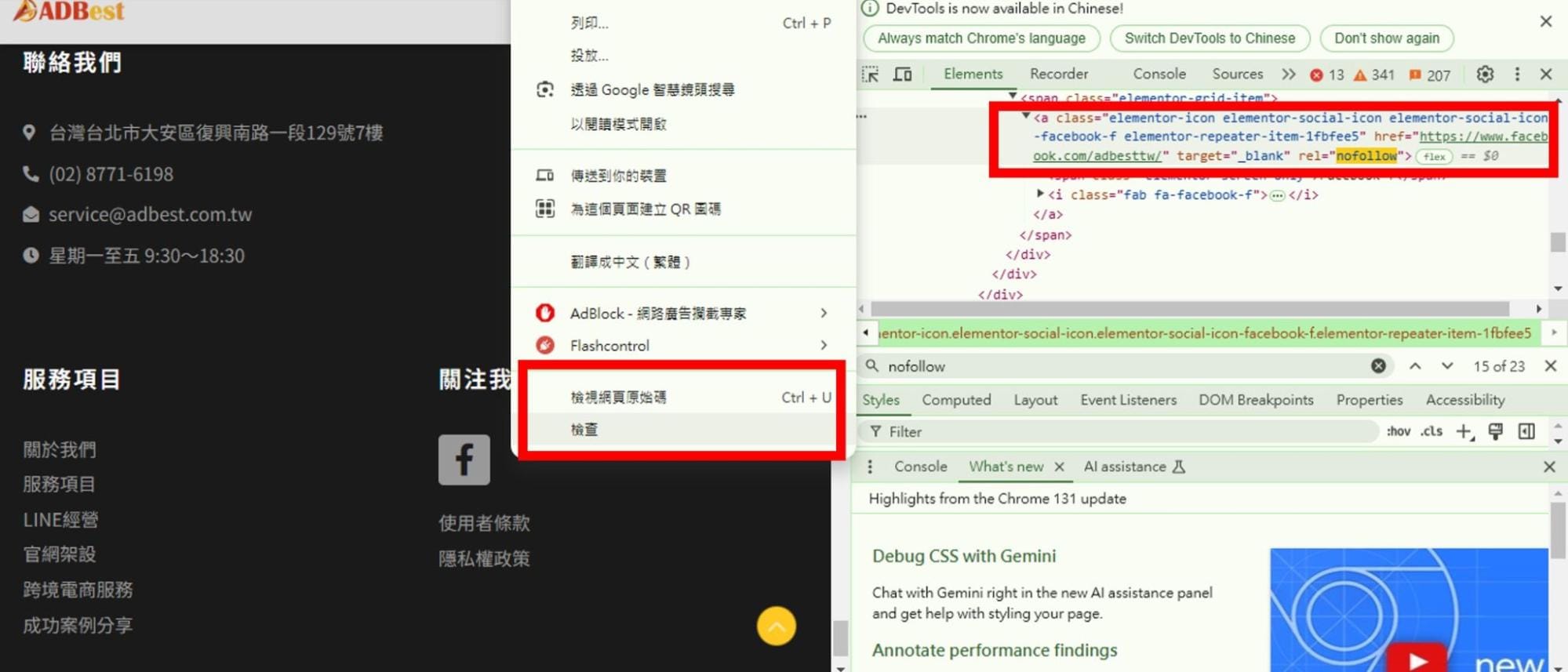
(一)查看 nofollow 方式1:確認 HTML 原始碼
- 在網頁上找到你想檢查的連結。
- 在該連結上點擊右鍵,選擇「檢查」或「查看原始碼」。
- 此時瀏覽器會開啟開發者工具,並自動定位到選定連結的 HTML 程式原始碼。
- 在連結的 <a> 標籤中,查看是否存在 rel=”nofollow” 屬性。
- 如果有,表示該連結已設置為 nofollow。
- 如果沒有,則該連結會讓搜尋引擎向目標連結正常傳遞權重(也就是dofollow)。
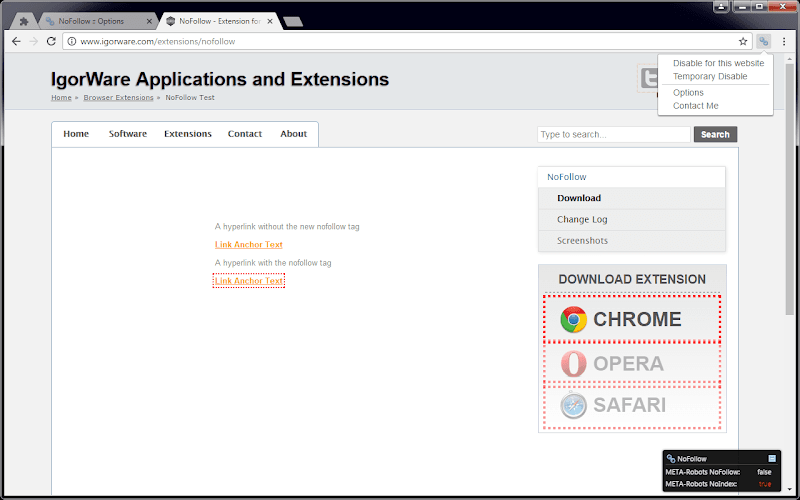
(二)查看 nofollow 方式2:使用外掛工具
- 前往 Chrome 線上應用程式商店。
- 在搜尋欄輸入「nofollow」,找到相關的外掛工具,例如「nofollow」、「Follow, Nofollow Link Checker」。
- 點擊「加入 Chrome」按鈕,安裝該外掛。
- 安裝完成後,該外掛會自動在網頁上標示出設置了 nofollow 的連結,通常以紅色虛線框顯示;其餘無特別設定的 Dofollow 則會正常顯示。
- 透過這種視覺化的方式,可以快速辨識網頁上哪些連結使用了 nofollow。
nofollow、Noindex 和 Robots.txt 差在哪?3差異一次說清楚!
nofollow、Noindex 和 Robots.txt 是 3 種用來控制搜尋引擎行為的工具。它們在使用目的、使用方式,以及對檢索和索引的影響上各有不同。
(一)使用目的
- nofollow:告訴搜尋引擎不要追蹤特定的連結、避免權重被瓜分。
- Noindex:指示搜尋引擎不要將特定頁面納入索引,在搜尋結果頁面就會排除標記 Noindex 的頁面。
用於不希望出現在搜尋結果中的頁面,例如隱私政策、測試中未完成的頁面。
- Robots.txt:用來告訴搜尋引擎爬蟲哪些頁面或特定目錄不應該被檢索,目的分為 2 種:
- 保護網站隱私和安全
- 降低爬檢索預算。
一來是用於防止搜尋引擎抓取特定內容,例如網站管理後台入口、敏感內容、重要性較低或是內容高度重疊的內容(程式碼、圖片資料等內容)。
另一方面,爬蟲每天在一個網站上的抓取次數是有限的,這被稱為「爬蟲預算」。
透過 robots.txt 排除不重要的頁面,爬蟲就能把更多資源用在抓取高價值的頁面,如產品頁、文章頁等,有助於更快地將這些頁面索引到搜尋引擎。
(二)使用方式
- nofollow:在 HTML 連結標籤 <a> 中加入 rel=”nofollow” 屬性,例如:<a href=”https://adbest.com/123″ rel=”nofollow”>錨文字</a>。
- Noindex:在頁面的 <head> 區域中加上 Meta 標記,例如:<meta name=”robots” content=”noindex”>。
- Robots.txt:在網站目錄建立 robots.txt 檔案,使用 Disallow 指令指定不希望被檢索的路徑,例如:Disallow: /private/。
(三)對檢索與索引的影響
- nofollow:搜尋引擎會檢索該連結,但不會追蹤或傳遞權重給目標頁面。
- Noindex:搜尋引擎可以檢索該頁面,但不會將其納入索引,因此不會出現在搜尋結果(SERP)中。
- Robots.txt:阻止搜尋引擎檢索指定的頁面或特定目錄,但如果其他網站連結到這些頁面,搜尋引擎仍有可能將其索引。
| nofollow、Noindex 和 Robots.txt 差在哪? | |||
| nofollow | Noindex | Robots.txt | |
| 對象 | 特定連結 | 特定頁面 | 網站、目錄 |
| 功能 | 告訴搜尋引擎「不要傳遞權重給特定連結」 | 指示搜尋引擎「不要將這個頁面納入索引」,讓它不出現在搜尋結果中。 | 告訴搜尋引擎「不要檢索這些頁面或資料夾」,限制爬蟲抓取範圍。 |
| 時機 | 當你連結到不信任或不相關的網站,或在付費連結、使用者生成內容中,避免影響網站權重時使用。 | 不希望特定頁面(如隱私政策、測試頁面)出現在搜尋結果中時使用。 | 希望限制搜尋引擎爬蟲訪問網站的特定部分(如敏感內容、程式碼、高度重疊的內容)時使用。 |
| 是否影響檢索? | 不影響,搜尋引擎仍會檢索該連結,但不會追蹤目標頁面。 | 不影響,搜尋引擎仍會檢索該頁面,但不會將其納入索引。 | 影響,搜尋引擎爬蟲會遵循指令,不檢索被禁止的頁面或資料夾。 |
| 是否被檢索 | 不影響,目標頁面仍可能被索引,但不會傳遞權重。 | Noindex 的頁面可能被檢索,但不會出現在搜尋結果中。 | 可能仍會被搜尋引擎索引,但不會抓取其內容。 搜尋引擎可能透過外部連結或其他途徑發現頁面。 |
如果你的網站沒有在搜尋結果中出現,你不只流失大量的客戶,競爭對手也正在用 SEO 蠶食你的訂單!
想透過 SEO 增加業績嗎?立即聯繫 ADBest!

延伸閱讀
🎈Img Alt攻略!4優化技巧+5地雷,讓搜尋引擎懂你的網站
