

文章最後修改於 2026-01-16
Robots.txt 是什麼?分享 robots.txt 對 SEO 的 4 大重要性!
robots.txt 一個存放在網站根目錄的純文字檔案,用來對搜尋引擎爬蟲表明網站中「哪些地方該檢索、哪些地方不用浪費時間」,避免爬蟲把不必要的頁面抓取進索引。
若是網站沒有設定 robots.txt,搜尋引擎預設會認為整個網站的所有頁面都可以自由爬取;若有加上 robots.txt 的設定,則會根據你的規則爬取頁面。
在開始理解 robots.txt 前,我們先搞懂兩個搜尋引擎的基本動作:
🔍 Crawl(檢索):搜尋引擎爬蟲會像小蟲一樣,到處「爬取」你的網站,把看到的內容一一記錄下來。
📂 Index(索引):將爬蟲看過的內容整理放進搜尋引擎的資料庫,之後在使用者搜尋時才能出現在搜尋結果裡中。
而 robots.txt 就是在檢索「找到網頁」的步驟中,直接向引擎爬蟲說明哪些頁面可以看、哪些不能看,幫助網站更有條理地分配有限的抓取資源。
可以想像你家門口貼著告示牌,寫著「訪客請走大門,後門不開放」,但這個告示只是個沒有強制力的提醒,並不是真正的門鎖。
所以像 Googlebot 這類守規矩的爬蟲會照做,但壞心眼的爬蟲卻不一定會聽話,甚至可能故意闖進你不想讓人進入的區域。
需要注意的是,robots.txt 的名稱必須使用全小寫,如果寫成大寫(像 Robots.txt 或 ROBOTS.TXT),錯誤的名稱會導致搜尋引擎無法讀取。

Google 官方也說明:robots.txt 主要是用來減少爬蟲對網站的壓力,以免伺服器被太多請求拖慢速度,但不是讓特定網頁從 SERP(搜尋結果頁)中消失。
因此,robots.txt 雖然不是強制必備,但卻能幫網站:
- 提升網站收錄與排名:在 robots.txt 裡放上 Sitemap,讓搜尋引擎更快把重要頁面收錄進資料庫。
- 避免爬蟲浪費資源:robots.txt 讓爬蟲馬上知道哪些地方可以爬取,讓搜尋引擎在處理網站內容時可以更有效率
- 避免重複內容影響 SEO:有時網站會有不同網址卻顯示一樣的內容(像商品頁分尺寸),使用 robots.txt 就可以幫忙擋掉這些頁面,避免重複收錄。
(一)為什麼 robots.txt 重要?
你可能會想:「SEO 不是就應該讓網頁被多多收錄,提升自然流量嗎?為什麼還需要限制爬蟲?」
更精確的解釋,robots.txt 不是拿來「阻止」搜尋引擎收錄所有內容,而是幫忙「指路」,讓爬蟲知道哪些地方值得看,哪些地方別浪費時間,而這麼做的好處主要有四個:
📝 原因 1:管理爬蟲檢索預算
每個網站每天能被搜尋引擎爬蟲花費的「爬取資源」是有限的,如果爬蟲把時間都花在購物車、後台或重複的網址頁面,真正重要的文章和產品頁反而可能延遲被索引。
運用 robots.txt,就可以讓爬蟲把檢索預算放在更應該曝光的內容,提升內容被收錄的效率。
📝 原因 2:網站後台不需要曝光
你的網站後台(像是 /admin/ 或 /login/)是給管理員用的,不需要開放所有人都能看見,當然不用出現被爬蟲給爬取。
📝 原因 3:某些資料夾根本沒用
網站裡可能有些技術性的檔案、程式碼,或臨時檔案(像 /tmp/、/scripts/),對搜尋引擎來說沒意義,反會佔用爬蟲抓取預算,導致真正重要的頁面沒被優先收錄。
📝 原因 4:測試網站不該被搜尋引擎發現
有時候網站會有一個測試版,例如 test.example.com,是開發人員用來試驗新功能的地方,裡面的內容可能是假的或還沒調整好。
如果搜尋引擎不小心把這些內容收錄進去,不只影響正式網站的 SEO,還可能讓使用者誤闖測試網站,看到錯誤的資訊造成混亂。
(二)robots.txt vs. meta robots:主要差異
除了 robots.txt,還有另一種與搜尋引擎溝通的方式,那就是 meta robots。
📝 meta robots 是什麼?
meta robots 是一段放在網頁內的 HTML 標籤,用來告訴搜尋引擎「這個頁面能不能被收錄?能不能跟別的連結傳遞權重?」
| meta robots 的語法舉例: <meta name=”robots” content=”noindex, nofollow“> 這段程式的意思是: noindex → noindex 代表這個頁面不要收錄,不出現在搜尋結果裡。 nofollow → nofollow 表示這個頁面中的連結不要傳遞權重給別的網站。 |
📝 什麼時候會用 meta robots?
- 不希望特定頁面出現在搜尋結果(像隱私政策、感謝頁、重複內容)
- 不想讓搜尋引擎追蹤某些連結(如付費廣告、會員登入按鈕)
- 不想讓搜尋引擎建立快取頁(像頁面更新很快,不想讓使用者看到過期內容時)
📝 robots.txt vs. meta robots 差異比較
| robots.txt vs. meta robots 比較表格 | ||
| robots.txt | meta robots | |
| 位置 | 放在網站根目錄下 | 放在網頁內 |
| 檔案類型 | 一個獨立的文字檔案 | 使用 <meta> HTML 標籤設定 |
| 主要功能 | 告訴搜尋引擎「不要來爬這個頁面」 | 告訴搜尋引擎「即使你爬到了,也不要收錄」 |
| 影響範圍 | 影響整個網站或特定目錄 | 只影響單一頁面 |
簡單來說:
- robots.txt 是一開始就告訴爬蟲「不要來」,但並沒有實質阻擋能力。
- meta robots 則是讓搜尋引擎「就算爬到了,也不要放進搜尋結果裡」。
Robots.txt 運作指南!新手必看的運作 3 步驟+4 個組成元素!
爬蟲讀取 robots.txt 的過程大約可以分為三個階段:
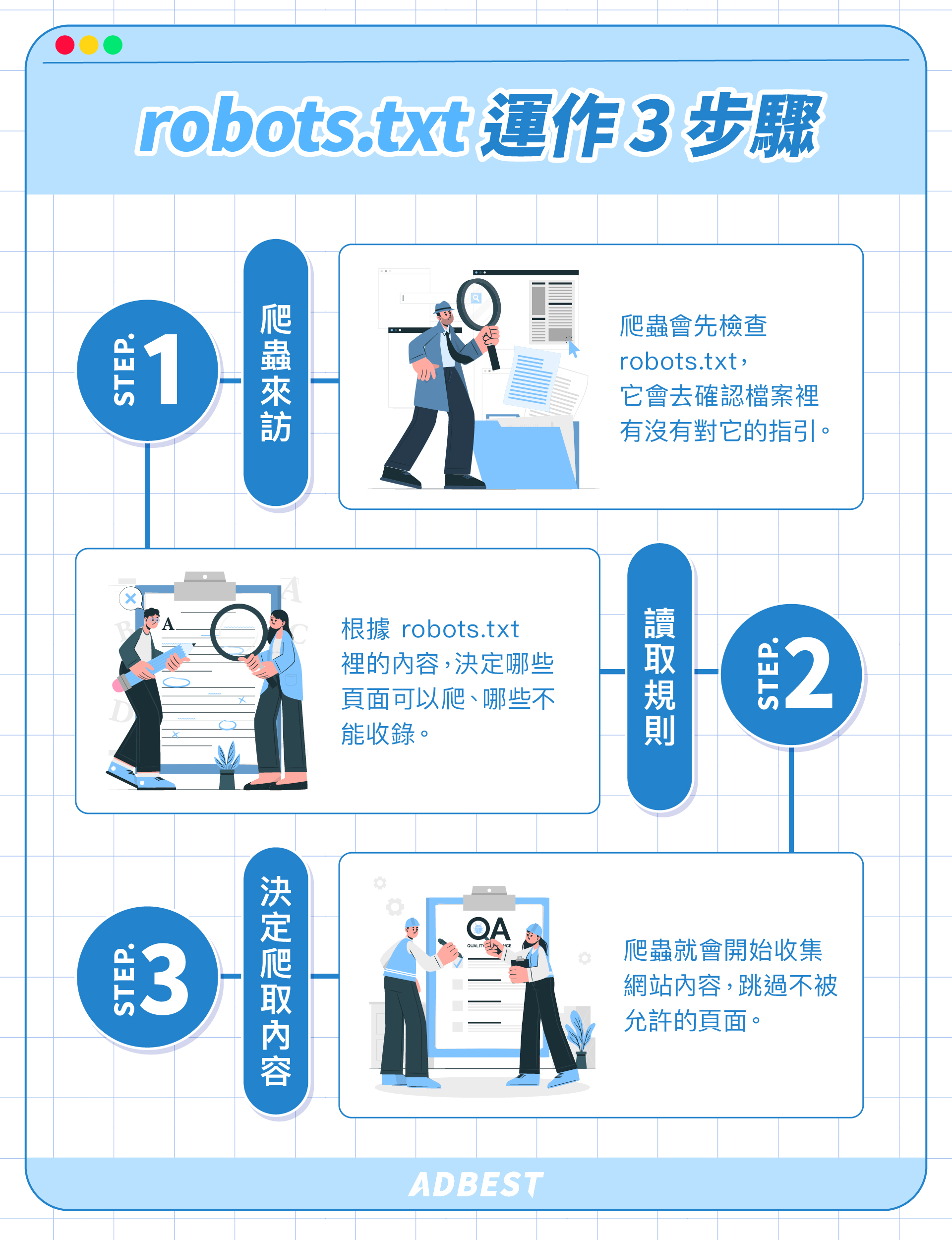
🔹 Step.1:爬蟲來訪
當搜尋引擎的爬蟲來到你的網站時,第一件事是先檢查 robots.txt,它會去確認檔案裡有沒有對它的指引。
🔹 Step.2:讀取規則
爬蟲會根據 robots.txt 裡的內容,決定哪些頁面可以爬、哪些不能收錄。
爬蟲會根據 robots.txt 裡的內容,決定哪些頁面可以爬、哪些不能收錄。例如:
| User-agent: * Disallow: /blog/ Allow: /blog/popular-post.html Sitemap: https://www.example.com/sitemap.xml |
這份 robots.txt 表示所有爬蟲都不能進入 /blog/ 這個資料夾;但 /blog/popular-post.html 這一頁可以例外。
以及提供一份地圖(Sitemap),請爬蟲按照這張地圖去爬取。
在接下來的段落,我們也會一一解釋組成 robots.txt 的元素。
🔹 Step.3:決定爬取內容
如果 robots.txt 允許爬取,爬蟲就會開始收集網站內容,並加入搜尋索引。
如果 robots.txt 說「不行」,守規矩的爬蟲就會跳過那些頁面。
(一)什麼是 User-agent?
User-agent 這個指令指明規則適用哪些爬蟲,也就是「這條規則是給誰看的」。
每個搜尋引擎的爬蟲都有自己的「名字」,像 Googlebot(Google 的爬蟲)、Bingbot(Bing 的爬蟲)、Baiduspider(百度的爬蟲)等。
網站可以針對不同的爬蟲設定不同的規則,決定哪些內容誰可以爬。
📝 User-agent:針對所有爬蟲的情況
如果你想讓所有搜尋引擎的爬蟲都遵守相同規則,可以用星號(*)代表「全部」。
| User-agent: * Disallow: /private/ |
這段 robots.txt 內容:意思就是:「所有的爬蟲(* 表示全部),請不要爬 /private/ 這個資料夾。」這樣任何爬蟲看到這個規則時,理論上都會遵守,不會去爬取。
📝 User-agent:針對特定爬蟲
有時候,你可能希望 Google 能看某些內容,但 Bing 不能看,那該怎麼辦?
這時候,你可以針對特定爬蟲寫不同的 User-agent 設定,像這樣:
| User-agent: Googlebot Disallow: /no-google/ User-agent: Bingbot Disallow: /no-bing/ |
這樣設定後,Googlebot 就不能爬 /no-google/,Bingbot 不能爬 /no-bing/,而其他爬蟲則不受影響。
📝 User-agent:常見的搜尋引擎爬蟲名稱
| 常見的搜尋引擎爬蟲名稱(User-agent) | |
| User-agent 名稱 | 作用 |
| Googlebot | Google 的主要爬蟲,負責一般網站索引 |
| Googlebot-Image | Google 專門用來抓取圖片的爬蟲 |
| Googlebot-Video | Google 影片搜尋專用的爬蟲 |
| Googlebot-Mobile | Google 用來爬行手機版網站的爬蟲 |
| AdsBot-Google | Google Ads 用來檢查廣告目標頁面的爬蟲 |
| Bingbot | Bing(微軟搜尋引擎)的主要爬蟲 |
| Slurp | Yahoo 搜尋的爬蟲,負責網站索引 |
| Baiduspider | 百度的主要網站爬蟲 |
| YandexBot | Yandex (俄羅斯搜尋引擎)的主要網站爬蟲 |
| Applebot | Apple 搜尋引擎(Siri、Spotlight)用的爬蟲 |
| Facebot | Facebook 用來抓取連結內容的爬蟲 |
(二)什麼是 Disallow、Allow?
📝 Disallow 是什麼?
Disallow 就是告訴爬蟲「這些頁面不要來爬取」的指令。
舉個例子,假設你的 robots.txt 這樣寫:
| User-agent: * Disallow: /admin/ Disallow: /private/ |
代表 /admin/ 以及 /private/ 兩個資料夾不允許被爬取。
但這些被 Disallow 擋住的頁面不代表它們完全隱藏,只是搜尋引擎不會主動去爬,如果別的網站連結到這些頁面,搜尋引擎還是可能會知道它們的存在。
📝 Allow 是什麼?
Allow 則是告訴爬蟲「這些頁面可以爬」的指令。
常用在「某個資料夾不給爬,但裡面有部分頁面可以爬」的情況。
舉個例子,假設你的 robots.txt 這樣寫:
| User-agent: * Disallow: /private/ Allow: /private/public-info.html |
這表示整個 /private/ 資料夾都不給爬,但是 /private/public-info.html 這一頁例外,可以讓爬蟲看得到。
📝 Disallow、Allow 常見使用舉例
- 阻擋整個網站:如果你的網站還在開發中,希望完全禁止搜尋引擎爬取你的網站的話,可以在 Disallow 後加上斜線。
| User-agent: *Disallow: / |
- 允許爬取所有內容:如果你希望搜尋引擎可以爬取整個網站,不做任何限制,那麼在 Disallow 後直接留空即可。
| User-agent: *Disallow: |
- 阻擋特定檔案類型:網站上特定檔案(例如 PDF、圖片、影片等)不希望被搜尋引擎索引
| User-agent: * Allow 則是告訴爬蟲「這些頁面可以爬」的指令,常用在「大範圍禁止,但局部開放」的情況。 Disallow: /*.pdf Disallow: /*.jpg Disallow: /*.mp4 |
- 阻擋特定 URL 參數:如果網站有動態網址參數(例如 ?sessionid=123),可能會產生重複內容。
| User-agent: *Disallow: /*?* |
(三)什麼是 Sitemap 指令?
除了用 Disallow 或 Allow 控制爬蟲行為,robots.txt 也能放 Sitemap 指令,就像一張「網站地圖」列出網站的重要頁面,讓搜尋引擎更快、更完整地認識網站。
在 robots.txt 裡加上 Sitemap 時,就等於直接把地圖交給爬蟲,告訴它:「這些頁面是重點,請優先檢索。」,主要有三個影響:
1.加快收錄速度:就算你的網站頁面很多、層級很深,利用 Sitemap,讓爬蟲直接知道有哪些頁面要檢索,提升收錄效率。
2.補足沒有內部連結的頁面:有些頁面可能沒有被其他頁面連結到(孤島頁),導致爬蟲難以發現。只要把這些頁面放進 Sitemap,搜尋引擎依然能找到。
3.不會覆蓋 robots.txt 的規則:Sitemap 只是提供「路線圖」,但不會影響 robots.txt 的規則。也就是說若某些頁面被 Disallow 禁止,就算它們在 Sitemap 中,爬蟲還是不會爬取。
robots txt 教學懶人包:一次教你搞懂語法、格式與位置!
(一)robots.txt 的基本語法與格式
Google 說明編寫 robots.txt 的流程:建立 robots.txt 檔案 ⭢ 新增規則 ⭢ 上傳至根目錄 ⭢ 檔案測試。
從上個段落中,我們說明了組成 robots.txt 的元素該如何使用,接著我們將解釋 robots.txt 的基本語法與格式:
- User-agent:這條規則是給誰看的?
- 設定爬蟲規則:分開管理不同的爬蟲
- Disallow:這裡不准進入!
- Allow:這裡可以進!
- Sitemap:來來來,這裡有地圖給你!
除了這五點組成之外,我們還可以額外加上「Crawl-delay」指令,告訴爬蟲每次請求之間要間隔多少秒數,以免網站負擔過重。
- Crawl-delay:你下次來訪時間,請至少間隔多久再來!
💡Crawl-delay 小提醒
需要注意並不是所有的爬蟲都支援 Crawl-delay 指令,像 Bingbot 和 Yandex 可能會遵守,但 Googlebot 從一開始就不支援。
雖然過去網站管理員可以利用 Google Search Console 手動調整 Googlebot 爬取速度,不過在 2024 年初,Google 官方也移除了這個功能。
因為 Google 認為系統自動調整會比人為設限更準確有效,但你仍然可在 GSC 的「檢索統計資料」報告中觀察:
- Googlebot 每天爬取多少頁面
- 爬取過程花了多少時間
如果數字異常高、網站也因此變慢,那就該考慮升級伺服器或優化網站效能了。
(二)robots.txt 範例
綜合剛剛學到的語法,舉例一個完整的 robots.txt :
| # robots.txt for https://adbest.com.tw/ # 針對所有爬蟲的基本規則User-agent: * Disallow: /admin/ Disallow: /private/ Allow: /private/public-info.html Sitemap: https://www.example.com/sitemap.xml # 針對 Googlebot 設定 User-agent: Googlebot Disallow: /test-pages/ Allow: /test-pages/google-only.html # 針對 Bingbot 設定 User-agent: Bingbot Disallow: /*.pdf Crawl-delay: 5 Sitemap: https://adbest.com.tw/sitemap.xml |
🔎 通用規則(適用所有爬蟲):
- 禁止爬取 /admin/ 和 /private/
- 但允許 /private/public-info.html 這頁例外開放
- 提供 Sitemap 讓爬蟲加速找到重要內容
🔎 針對 Googlebot 的特別規則:
- Disallow: /test-pages/ 👉 Googlebot 不能爬取 /test-pages/
- Allow: /test-pages/google-only.html 👉 但 Googlebot 可以爬取這份檔案
🔎 針對 Bingbot 的特別規則:
- Disallow: /*.pdf 👉 整個網站內 pdf 類型的檔案都不讓 Bingbot 爬取
- Crawl-delay: 5 👉 Bingbot 每次請求之間必須間隔 5 秒,減少伺服器負擔
這份 robots.txt 範例的設定方式可以作為通用模板參考,但不同類型的網站會有不同的需求,因此需要根據你的網站特性、SEO 目標、伺服器負載調整。

(三)robots.txt 位置與存取方式
📝 robots.txt 位置
robots.txt 的位置應該放在網站的根目錄,網址必須是:
| https://www.你的網站/robots.txt |
如果放錯位置,搜尋引擎爬蟲不會讀取。
📝 robots.txt 存取方式
robots.txt 的存取方式很簡單,只要在瀏覽器或任何工具裡輸入:
| https://想存取的網站.com/robots.txt |
就能直接看見 robots.txt 檔案的內容,我們也可以用這種方式檢查你的 robots.txt 設定狀態。
(在後面的段落,我們也會詳細介紹四種測試方法)
我們以 Apple 官網的 robots.txt 舉例:在瀏覽器輸入「https://apple.com/robots.txt」就會出現下圖。
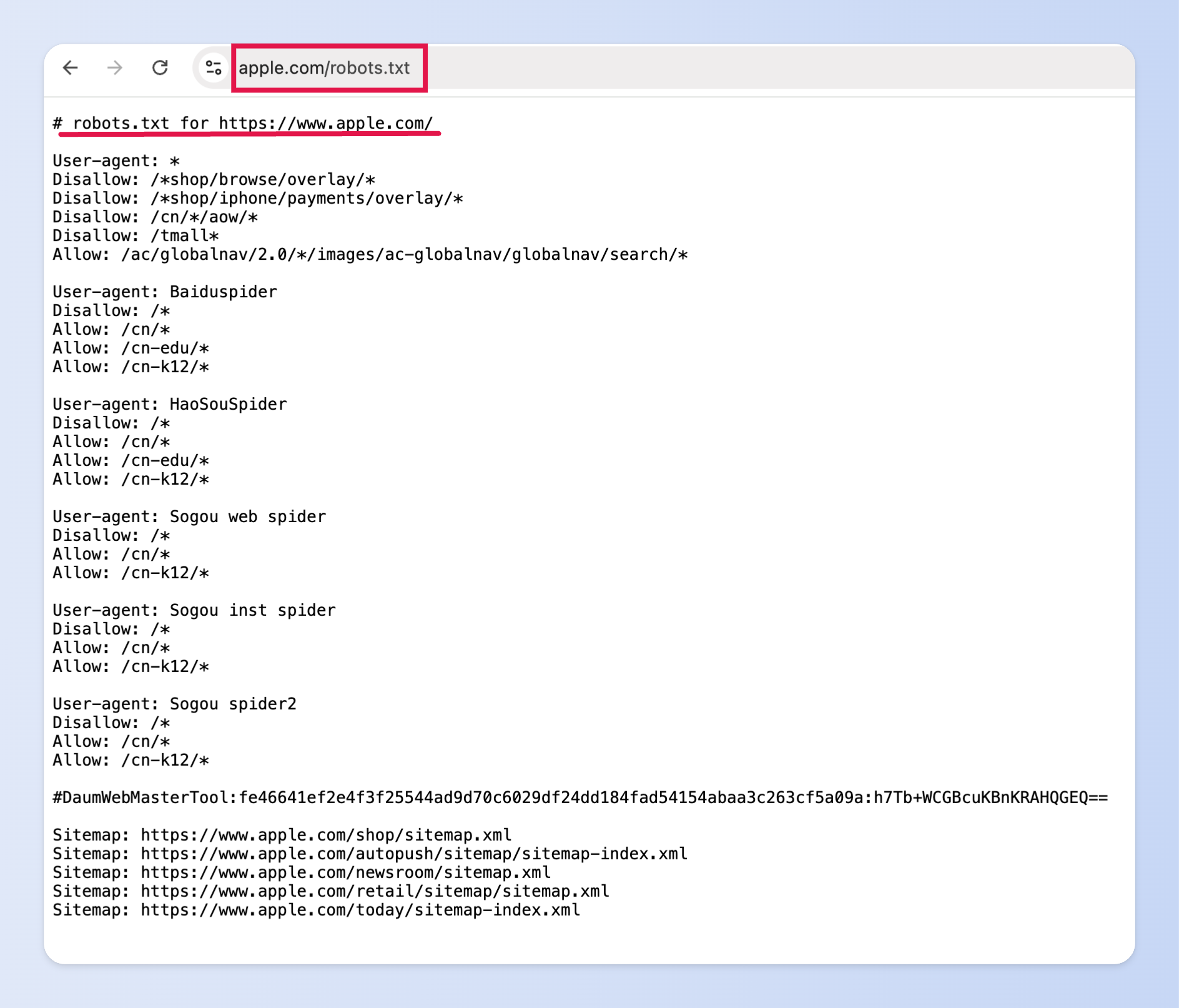
(圖片來源:apple.com)
有趣的是,許多品牌會在 robots.txt 裡加上彩蛋,讓品牌形象不只出現在頁面上,連 SEO 技術層面也充滿風格。
robots.txt 的彩蛋內容並不會影響網站運作,但對於喜歡挖寶、愛觀察網站細節的人來說,加上彩蛋就像不經意的小驚喜,讓人會心一笑。
(圖片來源:nike.com)

(圖片來源:cloudflare.com)
robots.txt 怎麼寫?5 種網站 robots txt 實戰教學!
不同網站在設定 robots.txt 時,會有不同的重點,像企業在意的是品牌內容能不能被快速收錄;而電商網站則需要避免購物車、結帳頁等頁面被收錄,才不會浪費爬蟲資源,也能讓 SEO 佈局更乾淨有效。
接下來,我們針對五種常見的網站類型,分享各自適合的 robots.txt 實際設定範例與操作重點,讓你可以直接套用在自己的網站上:
(一)企業網站 robots.txt 範例
| User-agent: *Disallow: /admin/ # 禁止爬取後台 Disallow: /login/ # 禁止爬取登入頁面 Disallow: /tmp/ # 禁止爬取暫存檔案 Disallow: /test/ # 禁止爬取測試頁面 Disallow: /private/ # 禁止內部文件 Sitemap: https://www.example.com/sitemap.xml |
🔹 企業網站設定重點
- 適合擋掉內部後台、內部文件、測試頁面,減少搜尋引擎爬取不必要的內容
- 加上 Sitemap,讓搜尋引擎更快找到品牌主頁、服務介紹、新聞稿等重點內容。
(二)電商網站 robots.txt 範例
| User-agent: *Disallow: /cart/ # 禁止爬取購物車 Disallow: /checkout/ # 禁止爬取結帳頁面 Disallow: /account/ # 禁止爬取會員中心 Disallow: /admin/ # 禁止爬取後台 Disallow: /search/ # 禁止內部搜尋結果頁 Disallow: /*?sessionid= Disallow: /*?filter=Disallow: /*?sort= Allow: /products/ Allow: /categories/ Allow: /blog/ Sitemap: https://www.example.com/sitemap.xml |
🔹 電商網站設定重點
- 應該擋掉購物車、結帳頁、會員頁、內部搜尋結果。
- 阻擋帶有 sessionid、filter、sort 等動態參數的網址,避免重複內容。
- 保留產品頁、分類頁、部落格文章的爬取權限,搭配 Sitemap 提升商品曝光。
💡小提醒
如果你是使用 91APP、Cyberbiz、Shopline 這類電商系統,要注意平台不一定能自由設定 robots.txt。
首先可以確認電商系統有沒有 robots.txt 設定功能,若是平台不支援,也可以評估使用 meta robots 標籤(例如設定 noindex、nofollow),阻擋搜尋引擎收錄特定頁面!
像是產品頁,有時候平台會預設支援 meta robots,但若是部落格文章、活動頁的內容型頁面,就不一定能手動加入,因為平台通常不開放修改 <head> 區塊,甚至找不到可以插入標籤的位置。
這時你還可以:
- 直接尋問平台客服能不能「封鎖特定頁面索引」、或請他們技術協助。
(三)新聞網站 robots.txt 範例
| User-agent: *Disallow: /admin/ # 禁止後台 Disallow: /login/ # 禁止登入頁面 Disallow: /drafts/ # 禁止草稿文章 Disallow: /preview/ # 禁止尚未公開的新聞預覽頁 Disallow: /test/ # 禁止測試環境頁面 Sitemap: https://www.news-example.com/sitemap.xmlCrawl-delay: 2 # 爬蟲請求間隔 2 秒,避免伺服器過載 |
🔹 新聞網站設定重點
- 擋住後台、登入頁、草稿文章與預覽頁,避免半成品或內部內容出現在搜尋結果中。
- 可以適度使用 Crawl-delay,因為新聞網站流量大、更新快,這樣能減少伺服器壓力。
- 加上 Sitemap,讓搜尋引擎快速找到最新新聞內容,提升時效性。
(四)部落格 robots.txt 範例
| User-agent: *Disallow: /drafts/ # 禁止爬取草稿文章 Disallow: /test-pages/ # 禁止爬取測試文章 Disallow: /admin/ # 禁止爬取後台 Disallow: /login/ # 禁止爬取登入頁面 Allow: /blog/ # 允許部落格正式文章被收錄Sitemap: https://www.example.com/sitemap.xml |
🔹 部落格設定重點
- 擋住草稿與測試頁,避免半成品或尚未完成的文章被收錄,影響專業度。
- 擋住後台與登入頁等沒有 SEO 價值的頁面。
- 開放正式內容頁,讓部落格文章、主題分類頁能被完整收錄,增加曝光機會。
- 加上 Sitemap 幫助搜尋引擎快速找到新文章,縮短從發文到收錄的時間。
(五)會員制網站 robots.txt 範例
| User-agent: *Disallow: /members/ # 禁止爬取會員專區 Disallow: /dashboard/ # 禁止爬取會員後台 Disallow: /account/ # 禁止爬取個人帳號頁 Disallow: /checkout/ # 禁止爬取結帳頁面 Disallow: /private/ # 禁止內部文件或隱私內容 Disallow: /search/ # 禁止內部搜尋結果 Allow: /public/ # 允許公開內容(例如免費文章或試閱頁面)Sitemap: https://www.example.com/sitemap.xml |
🔹 會員制網站設定重點
- 擋住會員專屬區域,像 /members/、/dashboard/、/account/ 等私人內容,不應該出現在搜尋結果。
- 擋住內部流程頁,如結帳頁、內部搜尋結果頁不具 SEO 價值,也可能浪費爬蟲資源。
- 果有試閱文章、免費資源,可以設定 Allow 來開放,讓搜尋引擎幫忙曝光。
- 加上 Sitemap 集中收錄重點公開內容,幫助搜尋引擎快速找到文章。
4 個方法檢查 robots txt!Google Search Console 測試流程一次看!
(一)robots.txt 測試工具
1️⃣ 測試方法:直接在瀏覽器輸入想測試的網址
最簡單的方法就是輸入網址手動打開 robots.txt,看看內容是否正確。
如果 robots.txt 存在,會直接顯示出設定的內容;如果顯示 404 Not Found,代表這個檔案不存在,需要重新確認放置的位置!
Step.1:先找到網站首頁的正確網址,例如 Muji 台灣官網 https://shop.muji.tw/
Step.2:在網址最後面直接加上 /robots.txt,就會變成:https://shop.muji.tw/robots.txt
Step.3:在瀏覽器輸入並打開,若網站有 robots.txt,你就會看到一個純文字檔寫著網站的爬蟲規則

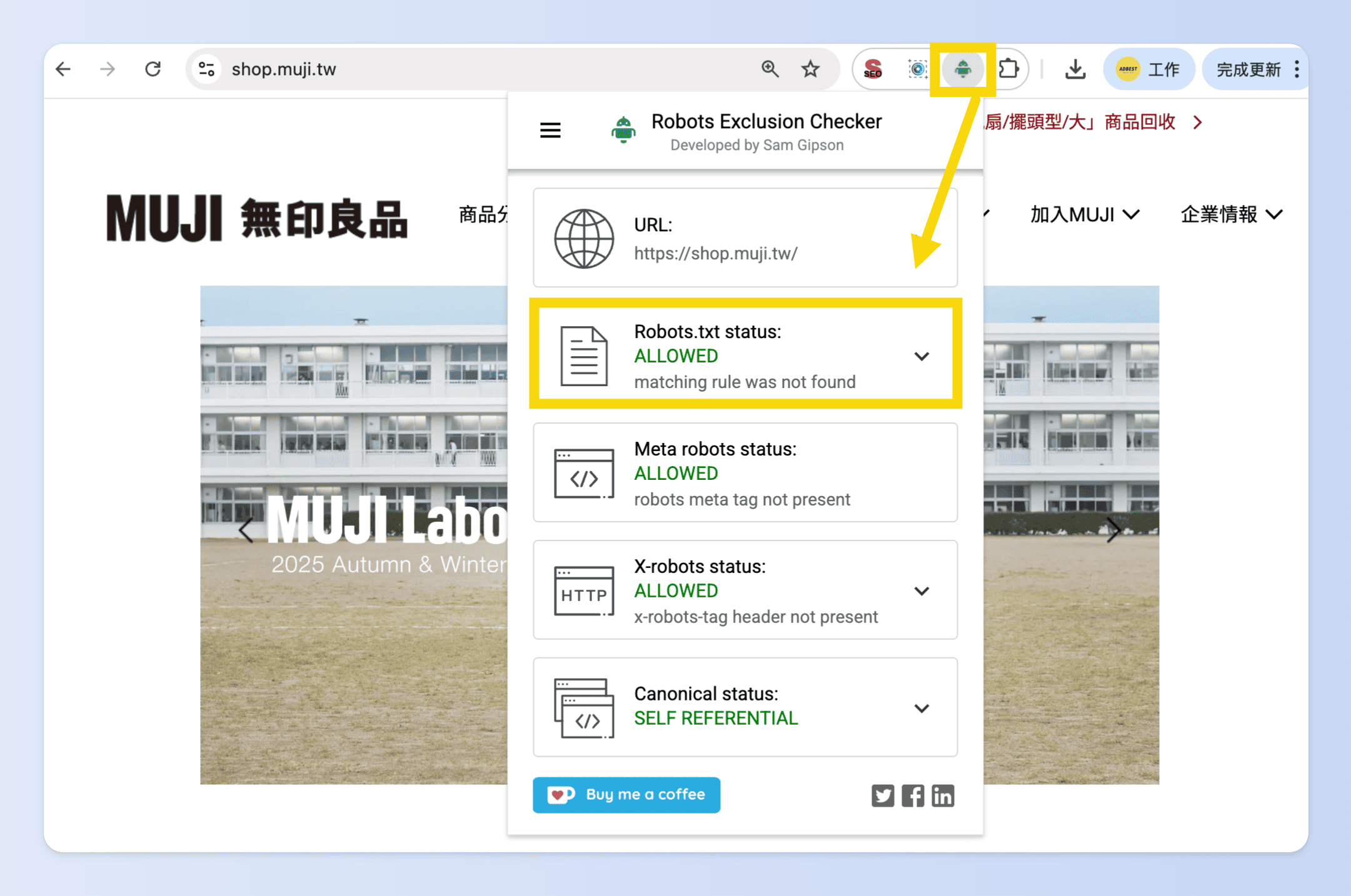
2️⃣ 測試方法:使用 Chrome 擴充功能測試
如果不想每次都手動輸入網址檢查 robots.txt,或想要快速檢查多個網站爬取規則,最快的方法就是安裝 Chrome 外掛測試,例如:
Step.1:打開 Chrome 線上應用程式商店,安裝擴充功能
Step.2:打開你要測試的網站頁面
Step.3:點擊擴充功能圖示
- 如果是 Robots Exclusion Checker → 會顯示頁面是否被 robots.txt 擋掉
- 如果是 SEO Minion → 除了檢查 robots.txt,還會顯示 meta robots 標籤設定(像 noindex、nofollow)
測試時,記得不只要看首頁,還要點進「產品頁」、「分類頁」、「搜尋頁」這類不同類型的頁面,因為有些網站只限制部分區域。
3️⃣ 測試方法:透過「爬蟲模擬工具」測試
如果你想要更全面地檢查整個網站,而不是只看單一頁面,可以用專業 SEO 工具來模擬爬蟲行為。
Step.1:下載或登入工具
- 安裝 Screaming Frog SEO Spider(免費版可測 500 頁)
Step.2:在工具的輸入框中填入要測試的網址,開始模擬搜尋引擎爬蟲抓取內容
Step.3:查看 robots.txt 測試結果
4️⃣ 測試方法:Google Search Console
Google Search Console(GSC)是 Google 官方提供的工具,能讓你直接測試 robots.txt 是否有擋住該擋的頁面。
接下來我們將介紹 Google Search Console 的測試流程!
(二)Google Search Console(GSC)測試工具流程
GSC 是網站的後台管理中心,因此它只能用來測試你已經完成驗證、擁有管理權限的網站,而不能隨意檢查別人的網站。
Step.1:進入 Google Search Console(GSC),找到左側欄位的「設定」
Step.2:點擊進入檢索中的「robots.txt」

- Step.3:在面頁中確認你設定的 robots.txt 狀態是否正確
以 ADBest 官網(https://adbest.com.tw/robots.txt)為例,狀態正常的話會顯示「已擷取」。
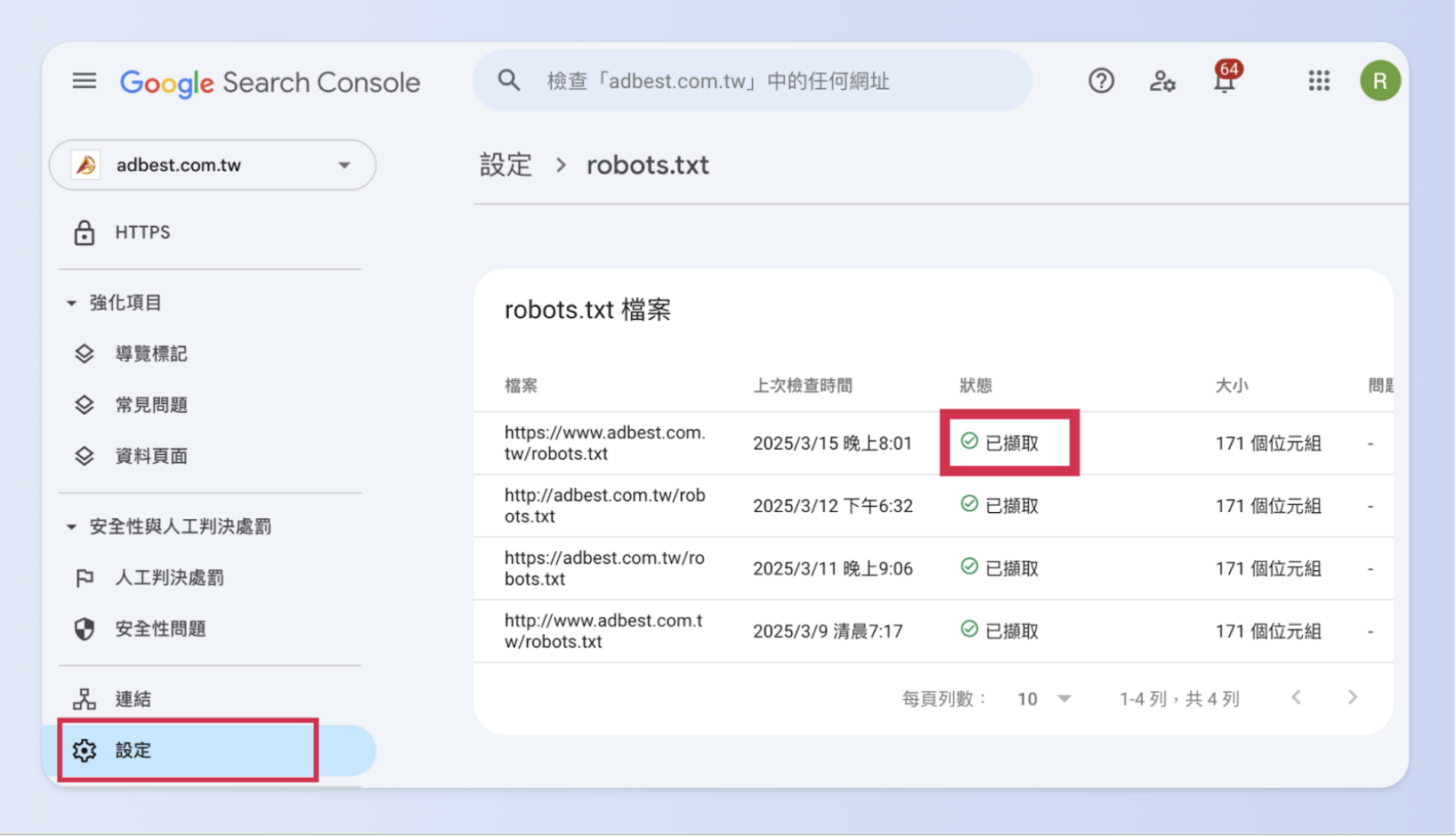
除了已擷取的正常狀態外,其他可能出現的顯示包括:
- 未擷取 – 找不到 (404)
- 未擷取 – 其他原因
詳細的說明可以參考 Google 官方說明!
Robots.txt 進階技巧!讓爬蟲乖乖聽話,保護隱私資料!
(一)如何封鎖特定爬蟲(如壞爬蟲、惡意爬蟲)?
因為 robots.txt 只是「建議」爬蟲怎麼做,但如果真的要阻擋壞爬蟲存取,更有效的做法是使用 .htaccess(Apache)、Nginx 設定或 Cloudflare 來封鎖惡意 User-agent。
🚧 使用 .htaccess 封鎖特定 User-agent(適用 Apache 伺服器)
在 Apache 伺服器使用 .htaccess的設定會直接拒絕惡意爬蟲訪問,比 robots.txt 更有效:
| RewriteEngine OnRewriteCond %{HTTP_USER_AGENT} ^BadBot [NC,OR]RewriteCond %{HTTP_USER_AGENT} ^EvilScraper [NC]RewriteRule .* – [F,L] |
🚧 在 Nginx 伺服器封鎖惡意爬蟲
如果你的網站使用 Nginx,可以這樣設定:
| if ($http_user_agent ~* (BadBot|EvilScraper) ) { return 403;} |
🚧 使用 Cloudflare 防火牆
如果你使用 Cloudflare,可以在防火牆規則(Firewall Rules) 裡設定「封鎖特定 User-agent」:
- Step.1:進入 Cloudflare 儀表板
- Step.2:點選 「安全性」 > 「WAF」
- Step.3:建立新的防火牆規則
條件(Condition):User-Agent 包含 BadBot 或 EvilScraper
行動(Action):Block(封鎖)或 Challenge(驗證)
(二)如何設定 robots.txt 來保護敏感資料?
robots.txt 不是一個安全機制,但它可以用來減少搜尋引擎爬取敏感資料(像隱私資料)的機會。
如果想防止自己的網頁出現在搜尋結果,建議使用 meta robots noindex 指令,或加上密碼保護網頁安全。
robots.txt 只是 SEO 的開始!ADBest 提供完整方案,讓網站排名穩步上升!
robots.txt 設定錯誤,可能會影響網站的 SEO 收錄與排名,甚至讓 Google 忽略你的重要頁面!
讓該擋的頁面沒擋好,搜尋引擎又可能抓到重複內容、內部搜尋結果,影響網站品質…
🚀 別讓 SEO 問題影響你的業績!ADBest 幫你解決!
ADBest 提供專業 SEO 優化服務,不只是設定 robots.txt,還會全面檢查你的網站 SEO,讓搜尋引擎能正確爬取、索引、排名!
不論你是企業官網還是電商網站,ADBest 都能提供量身訂製的 SEO 優化方案,讓你的網站被 Google 喜歡,更被客戶看見!
讓品牌網站主動出現在受眾眼前
👉 透過關鍵字研究與競爭分析,讓品牌瞬間出現在搜尋引擎首頁
👉 設計可持續的內容與技術策略,確保網站長期保持高排名
👉 從網站優化到內容撰寫,助力品牌提高自然流量與轉化提升

延伸閱讀
🎈Schema全攻略!完整解析33種結構化資料標記,你該用哪一種?
🎈301轉址教學大全!301/302差異解析,沒設定好網站流量歸零!
