

文章最後修改於 2025-12-19
LLM 是什麼?一次看懂 LLM 的 4 大優勢與 4 項缺點!
(一)LLM 意思
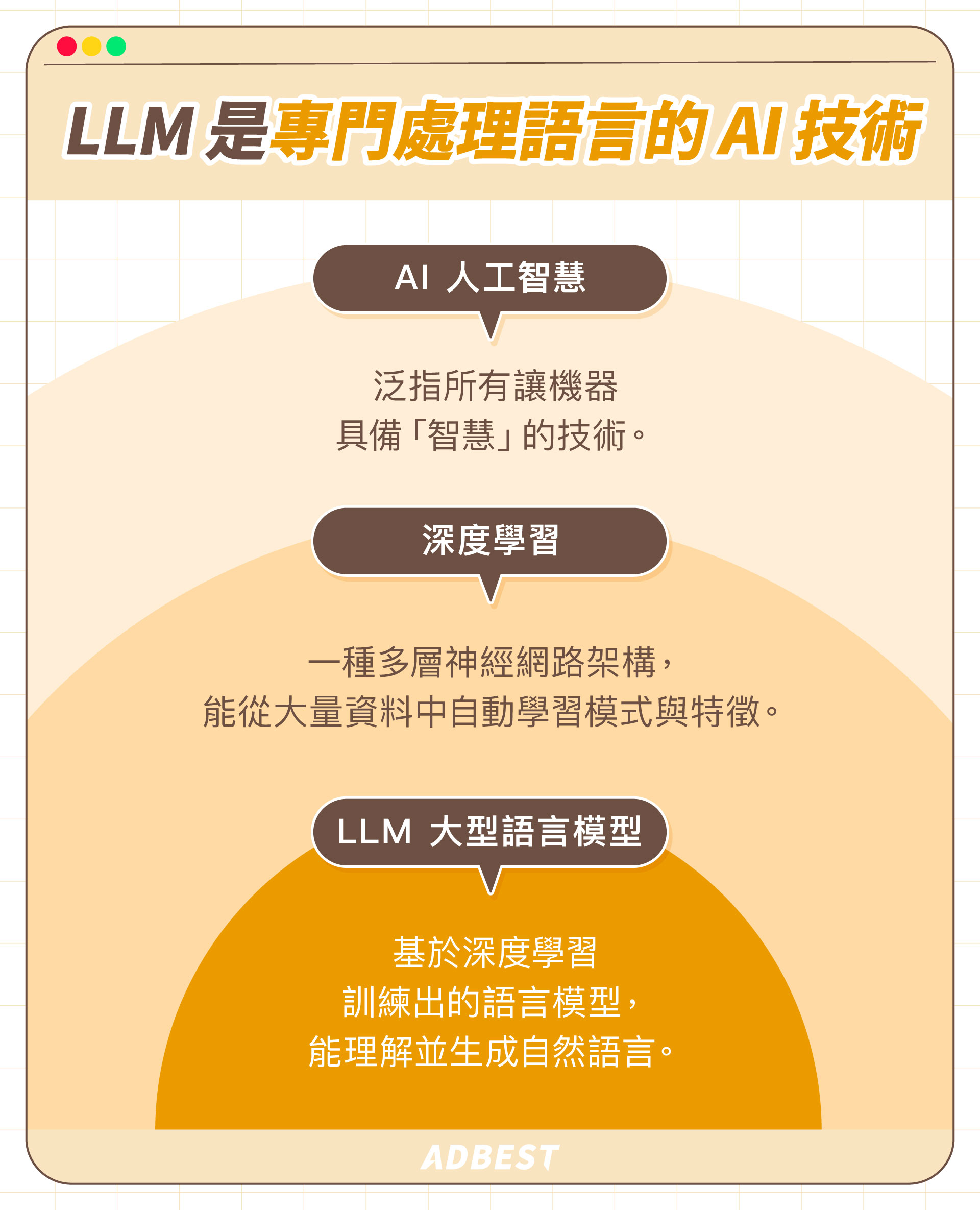
LLM 是「大型語言模型」Large Language Model 的縮寫,是一種專門處理語言的 AI(人工智慧)技術,也是目前 AI 領域中最具代表性的技術之一。
「理解人類語言並做出自然的回應」是 LLM 的核心,讓 AI 能看懂語句背後的語意、語氣、邏輯,再依據上下文延續對話、自行組合出沒有出現在資料庫當中的全新段落回覆。
LLM 能協助撰寫內容、整理摘要、翻譯語言、情感分析,幾乎涵蓋所有與「語言」相關的應用場景。
從技術層面解釋,LLM 是使用一種叫做「深度學習」的 AI 技術所而成。
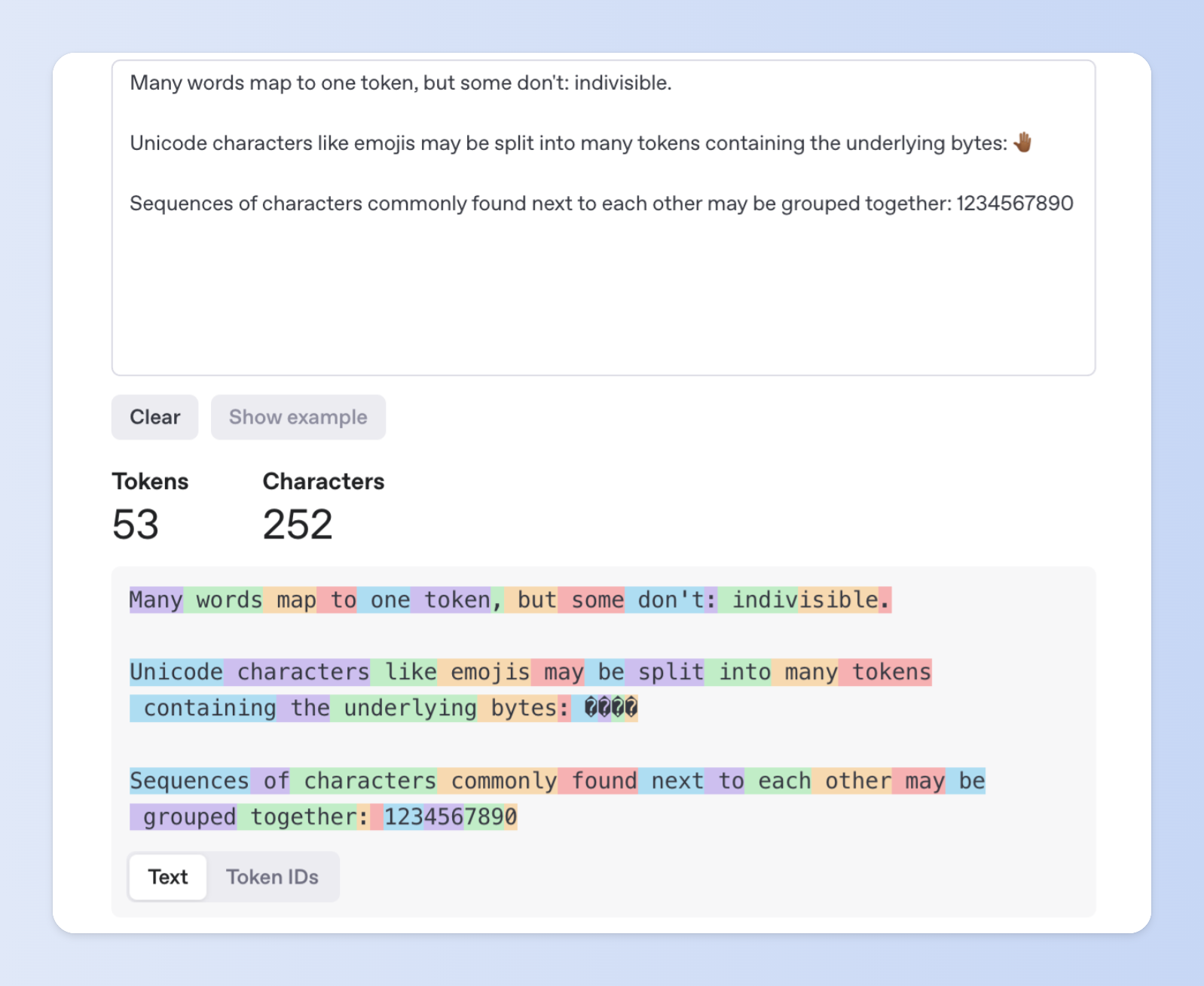
它會讀進非常龐大的文本資料,像是網路文章、書籍、論壇留言,再將這些內容切割成一連串稱為「Token」的基本單位,而模型就是靠這些 Token 來理解與預測語言。
在訓練過程中,模型會反覆分析這些 Token 序列之間的關聯,逐步建立出一套包含數千億個參數的系統。
參數就像成千上萬個細緻的判斷點,幫助模型決定「下一個詞是什麼」、「語氣應該如何延續」,或「使用者背後真正的問題是什麼」,最終生成流暢且貼近人類語感的回應。
| 📝 名詞解釋:Token Token 是語言模型處理文字時使用的最小單位,它可能是: ·一個單字(例如:apple) ·一個字母(例如:a) ·一段詞根或拼字片段(例如:tion) ·有時候也可能是無意義的字串(像是 ing、th) 因為語言模型使用的是數學運算和向量表示,它不會「讀」句子,而是將句子切成一長串 Token,再用數學方式處理這些 Token 的關係和順序。 |
目前主流的 LLM,像是 OpenAI 的 GPT 系列、Google 的 Gemini、Anthropic 的 Claude、xAI 的 Grok 等,參數數量都動輒上千億,具備極強的語言處理與生成能力。
對企業或品牌來說,LLM 能夠提升工作效率,也帶動企業在數位轉型上的應用,更是未來競爭力的重要一環。
(二)LLM 模型:4 項優點
📝 LLM 優勢 1:靈活多元的應用能力
LLM 能夠處理各種語言任務,甚至還能模擬對話風格或特定品牌語氣,讓它不只能用在單一場景,而是可以橫跨行銷、客服、教育、內容製作等多種產業用途,輕鬆整合到各種工作流程中。
📝 LLM 優勢 2:高準確性與理解能力
相較早期的語言工具,LLM 最大的突破之一是「讀得懂上下文」。
它不只是從單字判斷,而是能掌握整段話的邏輯、情緒及語境,回應方式更自然、更貼近人類口吻,讓它在處理複雜問題、生成專業內容時更為可靠。
📝 LLM 優勢 3:自動化與提升效率
LLM 能在短時間內自動完成大量文字工作,像是編寫產品說明、產出社群草稿、整理訪談紀錄、撰寫 FAQ 回覆等原本需由人工處理的文字任務,都能用 AI 快速處理、再由人力優化。
除了大幅節省時間,也讓內容產出流程更穩定、效率更高。
📝 LLM 優勢 4:可擴充性與高度彈性
LLM 的設計可以搭配各式系統、資料庫與應用平台進行整合,也能依企業需求客製化調整回答方式或知識範圍。
無論是導入到自有 App、企業內部搜尋系統,或結合客服機器人使用,都能根據不同產業、語言或任務彈性調整,具備極高的延展性。
(三)LLM 模型:4 項缺點
📝 LLM 缺點 1:AI 幻覺現象(Hallucination)
LLM 有時會生成看起來合理、語句通順,但實際上「內容是捏造的」或「完全沒根據」的回答,稱為 AI 幻覺。
因為 AI 是根據資料的語言模式「推測」最可能的回應,而非它能真正像人類思考用字遣詞與邏輯,導致內容有誤。在需要準確資訊的情境中(如醫療、法律、財經領域)需要特別小心。
📝 LLM 缺點 2:高度依賴訓練語料
LLM 的能力取決於輸入的資料,也就是訓練語料,表示它「腦海中的知識」是來自它曾經讀過的內容。
如果某些領域資料偏門、語言使用族群少、或是近期才出現的全新知識,LLM 可能就無法準確理解或回應,可能會用舊資料推斷錯誤結論。此外,訓練語料的偏見也可能反映在生成的回應中,造成歧視。
📝 LLM 缺點 3:計算推理與數學能力有限
數學題常常需要有條理地推理、程式結構判斷、檢查結果,但 LLM 的核心目標是理解與生成語言,並沒有內建「運算邏輯」。
所以它不會真正計算,而只是根據語言規律模擬出「像是有人在解題的樣子」,預測哪個答案最常出現在類似語境中,而不是真的一步一步計算結果。
📝 LLM 缺點 4:訓練成本高昂
練與部署 LLM 需要非常龐大的運算資源,包括高效能 GPU、儲存空間與穩定的雲端架構。
其中所需的時間、人力與金錢成本都相當可觀。
LLM 怎麼運作?搞懂神經網路、深度學習與 Transformer!
(一)LLM 原理:深度學習
想要理解 LLM(大型語言模型)怎麼運作,有三個關鍵基礎:神經網路、深度學習及 Transformer 模型。
用比喻來理解,如果神經網路是設計藍圖,深度學習就是根據藍圖所打造能自我學習的機器,而 Transformer 模型就是這台機器中最先進的引擎。以下簡單介紹,幫助你快速理解:
📍 神經網路
神經網路(Neural Network)是一種模仿人類大腦神經元連接方式的運算架構。
在一個完整的神經網路中,包括三個主要部分:
1.輸入層:將文字變成資料。
2.隱藏層:進行分析與判斷。
3.輸出層:給出推測或回答。
舉例來說,LLM 收到一句話後,會先將文字轉成數值,經過數千個模擬神經元進行判斷,最後輸出最合適的回答。
神經網路運作的過程就像是模型的大腦思考,幫助它理解語意、分析語境,並做出語言上的推測。
📍 深度學習
深度學習(Deep Learning)則是使用很多層神經網路進行訓練的方式。
傳統的神經網路中,可能只有一兩層負責進行大部分判斷的隱藏層,能處理的任務比較基礎;而深度學習則堆疊更多層隱藏層,讓模型能一步步學會更複雜、更抽象的語言特徵。
像是淺層學會字詞關係,深層則能判斷句子重點、語氣轉折,或隱含的情緒。
深度學習也使 AI 擁有自我學習能力,讓 LLM 能從大量資料中提煉出語言規律,不再需要人手動設定每條語法規則,輸出的文字也更自然、邏輯更清楚。
(二)LLM 原理:Transformer 模型
Transformer 是專為處理語言資料設計的深度學習架構,能同時分析整段文字中詞與詞之間的關係,比傳統模型更擅長理解上下文與語意邏輯,為語言理解、對話系統、機器翻譯等應用打開了全新局面。
我們可以用很日常的簡單例子來舉例,幫助理解:
1.「她把牛奶倒進碗裡,直到它滿了為止。」
⮑ 句子中的「它」指的是「碗」,但若是在以下的句子中卻會出現不同的含義:
2.「她把牛奶倒進碗裡,直到它空了為止。」
⮑ 在這個句子中,「它」這次代表了「牛奶(瓶)」
這種語意上的差異,對人類來說幾乎是直覺理解,但對傳統模型來說卻是一大挑戰。
而 Transformer 模型的設計加入了「自我注意力機制(Self-Attention Mechanism)」,模型在處理「它」時,還會同時注意整句話中出現過的詞,並根據語境判斷出最合理的指涉對象。
Transformer 模型最早是 Google 在 2017 年的論文中所提出,迅速成為自然語言處理領域的主流,包括 GPT、BERT、T5 等知名語言模型,都是建立在 Transformer 的基礎上發展而來。
| LLM 運作根本依據 | |||
| 神經網路 Neural Network | 深度學習 Deep Learning | Transformer 模型 | |
| 含義 | 模仿人腦的架構,用來處理輸入與輸出資料 | 使用「多層神經網路」來學習資料特徵的方法 | 專門用來處理語言資料的深度學習架構 |
| 本質 | 架構 | 方法 | 架構 |
| 重點 | 模仿神經元傳遞訊號,進行分類或預測 | 自動從大量資料中學出特徵,減少人工設計 | 藉由注意力機制,理解詞與詞的關係 |
| 用途例子 | 情緒分類、手寫數字辨識等簡單任務 | 圖像辨識、語音辨識、語言模型訓練 | ChatGPT、Gemini 等語言 AI 的核心架構 |
| 相對關係 | 是最基本的單位與基礎結構 | 是神經網路的進化與應用方式 | 一種更先進的深度學習架構,專門處理語言問題 |
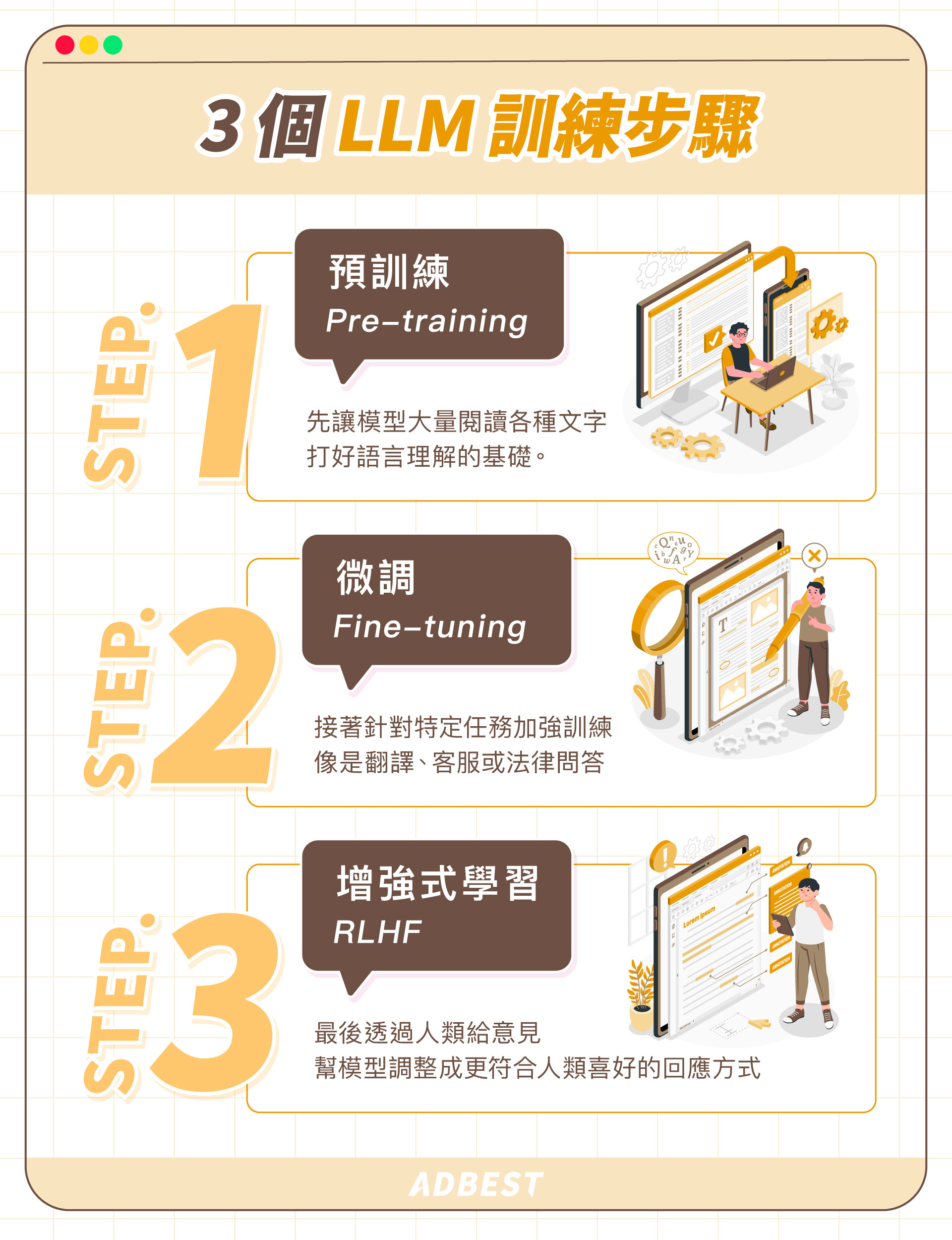
怎麼訓練 LLMs?3 步驟帶你看懂 AI 模型成長過程!
- 預訓練(Pre-training):讓模型從大量文本中學會語言基礎與語意關聯。
- 微調(Fine-tuning):針對特定任務或領域,進行進一步調整與訓練。
- 增強式學習(RLHF):藉由人類回饋優化模型行為,使回應更貼近人類偏好。
(一)Step.1:預訓練(Pre-training)
預訓練的目標,是讓模型具備語言的基本理解與表達能力。
藉由龐大的公開語料進行 AI 模型訓練,像是維基百科、書籍、新聞、社群平台內容等,轉成數值格式後餵給模型,讓它從中掌握語言的基本規律、邏輯結構、語意連貫性、詞彙搭配與語氣變化。
預訓練模型最常見的模式有兩種:
1.預測下一個詞:給它一句話,像「我今天心情很好,因為天氣很____」,它要推測出最合適的詞可能是「好」、「晴朗」或「舒服」;
2.補出缺漏的詞:就像是考卷上的填空題,把句子某個單字遮住,例如「我今天吃了 ___ 和水果」,讓模型根據前後語境猜出答案。
(二)Step.2:微調(Fine-tuning)
微調的過程,讓模型具備處理「特定任務」的能力,從泛用語感轉向實務 AI 應用。
在預訓練之後,模型雖然已經能理解語言、生成句子,但它並不知道如何應對特定情境。這時候,就需要「微調」進行再訓練。
微調的方式,是針對模型將要面對的任務,準備一份主題明確、格式一致的訓練資料。例如:
- 想訓練客服模型,就提供大量真實客服對話紀錄
- 想應用在醫療諮詢,就輸入醫病問答、醫學科普內容
- 想用於法律摘要,就餵它判決書、法條說明與法律 QA
這階段就像是「職前訓練」,讓 AI 從新進實習生的身份,轉變成具備實務技能、能勝任職位的專業人員。
(三)Step.3:增強式學習(RLHF)
最後一步,是以增強式學習讓模型回應更貼近人類偏好。
增強式學習與預訓練、微調最大的不同,在於它不是學習固定答案,而是根據人類的主觀回饋,利用不斷試錯與獎勵的方式,讓模型優化回應品質。
增強式學習中的 RLHF (Reinforcement Learning from Human Feedback)技術,是模型針對同一個問題產出多種回應,由人類進行評分或排序,讓模型學會貼合人類的價值觀。
這一階段要讓模型逐步學會避開不恰當的語氣、模糊的說法或答非所問的回應,讓表現從「能產出回答」進化為「回答得讓人滿意」。
大型語言模型如何應用?4 個場景&適用產業分享!
- 客服與聊天機器人:即時理解語意、流暢對答,降低客服成本、提升服務品質。
- 內容生成與文案寫作:快速產出多樣文案,維持語氣一致、提升內容效率。
- 企業知識管理與搜尋:用自然語言查詢內部知識,加強資訊存取與效率。
- 遊戲沉浸對話與娛樂:打造自然互動角色與劇情,提升遊戲體驗與創作彈性。
(一)客服與聊天機器人
LLM 能即時理解使用者語句背後的需求,理解語意、靈活應對,而不像傳統規則式機器人只能依照設定好的問題庫,從關鍵字比對中提供死板回應。
LLM 可以理解同一件事的不同說法,像是「我想退貨」和「這東西可不可以退」都能被正確解讀為同一需求,並提供指引。
此外,LLM 也能記住前後對話脈絡,像前一句問「這件衣服能換尺寸嗎?」後一句說「那我要 L 號」,模型仍能理解顧客指的是剛剛那件衣服,不會答非所問。
同時還能支援多語言對話,降低跨國服務的語言門檻。
適合電商、金融、電信、保險等,需大量客服支援的產業,能減少人工負擔、提升服務品質。
延伸閱讀🎈AI客服是什麼?5步驟拆解運作機制,7類型+8應用情境解析!
(二)內容生成與文案寫作
LLM 能根據指示快速產出語句通順、邏輯清楚的各類型內容草稿,大幅減少創作時間。
傳統寫作方式需要人員從頭構思、組織架構、反覆修改,而 LLM 可以根據主題、語氣風格或目標對象,生成語調一致且結構完整的內容。
同時,LLM 也能產出多版本文案,支援 A/B 測試,幫助行銷人員評估轉換效果。針對不同平台(如 Facebook、Instagram、EDM、網站)也能調整長度與語氣,讓內容更貼近受眾習慣。
適合的產業包括行銷、品牌、公關、媒體、出版與電商等需要大量內容輸出、重視語氣一致性與效率的工作場景。節省人力成本之餘,也能讓創作品質更穩定。
(三)企業知識管理與搜尋
LLM 能將企業內部龐雜的文件、手冊、會議紀錄等文字資料,轉換成可被理解與檢索的語意格式,讓員工不必死背檔案位置或關鍵字,而是能口語提問並取得精準答案。
傳統的知識管理系統通常依賴目錄分類與關鍵字搜尋,使用者必須輸入正確詞彙、手動比對資料內容,非常耗時且容易漏查。
相比之下,LLM 可理解問題背後的語意,也能從大量資料中抽取出最相關的段落或答案,快速回應,實現知識共享。
適合大型企業、醫療機構、顧問公司、金融與製造業等內部知識量大、文件繁複、跨部門協作頻繁的環境,提升運作效率、,避免資訊斷層。
(四)遊戲沉浸對話與娛樂
LLM 在遊戲與娛樂領域的應用,最核心的重點在於提升角色對話的自然度與真實感,打破傳統劇本制式選項,讓玩家與角色之間能展開自由的交流。
過去遊戲中的 NPC(非玩家角色)多半依照固定腳本回應,互動侷限、選項死板,難以讓玩家產生情感連結,而 LLM 能根據玩家回應自由生成對話內容,依角色設定維持一致語氣,還能隨劇情進展調整反應,讓角色更立體,世界觀更有沉浸感。
除了對話生成,LLM 也能支援開發過程中的創作任務,像撰寫任務描述、角色背景設定、世界觀草稿與支線劇情提案,大大加速內容開發流程。
這項能力不只適用遊戲產業,也延伸至互動小說、虛擬主播、AI 聊天伴侶等娛樂場景,為使用者帶來更豐富靈活的體驗。
LLM Model 常見 QA 精選整理!快速建立正確觀念!
(一)Q:LLM 和 AI 有何差異?
LLM 屬於 AI 之中的一個分支,專門處理語言相關任務。
AI 是統稱,涵蓋語音辨識、影像分析、機器學習等多種技術;而 LLM 則是其中專注於理解與生成自然語言的技術類型,像 ChatGPT、Gemini 就是基於 LLM 發展出的應用。
(二)Q:LLM 未來發展趨勢?
LLM 將朝更智慧、高效、安全與多元應用邁進。
未來的 LLM 會提升理解與推理能力,也會加強運算效率與資訊安全,同時融合圖像、聲音等多模態資料,支援更豐富的互動體驗。此外,模型也將更能因應個別使用者需求,實現客製化對話與任務處理,廣泛應用各種產業領域。
(三)Q:ChatGPT 是一種 LLM 嗎?
沒錯,ChatGPT 就是一種基於 LLM(大型語言模型)的應用。
它是由 OpenAI 所開發,底層採用 GPT 系列的大型語言模型,能理解提問、生成回應、進行多輪對話,是 LLM 技術的具體應用之一。
(四)Q:LLM 是開源的嗎?企業可以自行訓練嗎?
部分 LLM 模型(如 Meta 的 LLaMA、Mistral)是開源的,可供企業自行部署與微調。
但自行訓練 AI 需高運算資源與技術門檻,也可選擇使用 API 形式的商業服務(如 GPT、Claude)。
不只懂 LLM,ADBest 帶你實現真正落地的 AI 應用!
隨著大型語言模型(LLM)技術不斷進化,AI 正逐步滲透每個產業運作的核心,從語言理解、知識搜尋,到創意生成與智慧決策,未來的社會將與 AI 深度融合。
現在,已經不是該不該導入 AI 的問題,而是怎麼選對工具、走對方向,才能讓品牌在轉型的浪潮中穩健前行。
ADBest 不只是了解趨勢,更是懂你需求的實戰夥伴!
無論你剛起步探索,或是導入遇到瓶頸,ADBest 都會依據品牌的實際狀況與資源條件,協助你一步步走穩每個關鍵節點:資料如何準備、應用怎麼建、成效如何評估與優化,全都有專業團隊陪你一起走。
除了懂技術,也更懂市場與品牌的真實挑戰。
從 AI 導入規劃到 SEO、社群、電商、跨境整合行銷,ADBest 用策略整合每一個環節,把工具放在真正需要它的地方。
AI 不該只是潮流,它更是你未來成長的核心動力。
📩 現在就聯繫 ADBest,讓我們陪你一起用 AI 打開品牌成長的下一個突破口吧!
打造可落地的 AI 代理,從釐清需求開始
👉 深入了解不同企業的流程/業務痛點
👉 找出真正有用的 AI 應用場景
👉 一起規劃未來的 AI 策略與藍圖
👉 實際建構及開發 scalable 又安全的解決方案
延伸閱讀
🎈AI行銷全解析:4大優勢分析、5大市場趨勢及6款AI工具案例介紹!
🎈AI Agent是什麼?與AI差異?企業4思維+6應用分享!
🎈Zapier是什麼?5步驟設定教學、自動化應用、好處、費用一次看!
🎈n8n新手中文教學:6步安裝、7步驟部署第一支工作流!費用?

